


交易所指南
币圈新手在哪个平台玩合约和现货好?
在国内玩合约和现货最好的交易平台是币安和欧易,其次推荐火必、抹茶和Gate.io,不建议在小的交易所存放大资金,风险相对更大。
正规数字货币交易平台:5个最佳选择

本站将为大家介绍中国用户使用最多的5个正规数字货币交易平台,分别是:币安Binance、欧易OKX、火必、抹茶、Gate.io。
2024年BTC交易平台推荐 | 中国比特币交易平台
对比特币感兴趣的新手用户往往在瀚如烟海的网络中找不到BTC交易平台的正确信息,从而加大了进入加密货币世界的门槛。 本文将为大家介绍5个中国用户常用的比特币交易平台,覆盖三大交易所和仅次...
币圈新手如何选择可靠的加密货币交易所?

本文从币圈老用户的角度出发,从安全性、加密货币种类、用户界面和易用性、支付方式、交易手续费等方面为新手推荐合适的加密货币交易所,如:币安、欧易、火必等。
如何注册Gate.io芝麻开门交易所账户?

虽然注册帐户很简单,但是还是经常遇到有朋友问芝麻开门怎么注册,为什么注册不了这些问题。 下面简单的写下Gate.io账户注册和使用的教程: 第一步:打开注册地址:https://link.zhinitaimei.co...
如何注册抹茶交易所账户?

抹茶已经清退中国用户,目前没有看到重新回归的苗头。 表现为: 注册MEXC交易所账户时会发现无法使用中国手机号注册; QQ,163等国内邮箱都不能用来注册抹茶账户 禁止国内网络注册。 那么国内用...
如何给币安交易所逐仓U本位合约添加保证金?
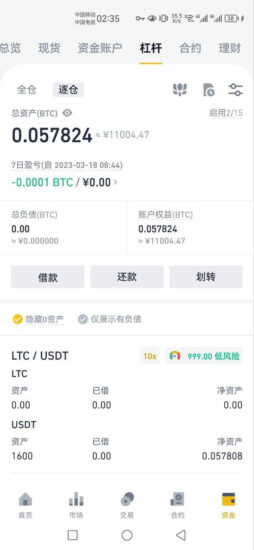
在币安交易所逐仓U本位合约中添加保证金时,用户需要先将资金划转到合约账户,并手动调整保证金。
如何充值或提现加密货币?
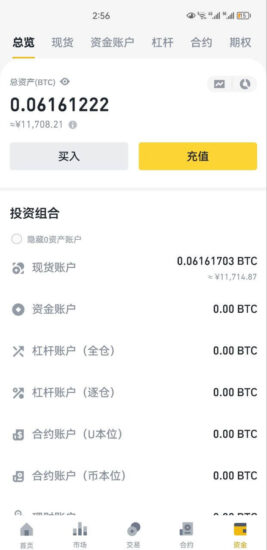
本教程将以欧易提现USDT到币安交易所的例子说明如何充值或提现加密货币。 一、欧易提现USDT到币安交易所 1、首先打开币安App,然后找到充值按钮,不用客气,狠狠地点击就行。 2、搜索usdt,点它...
如何在交易所进行永续合约交易?
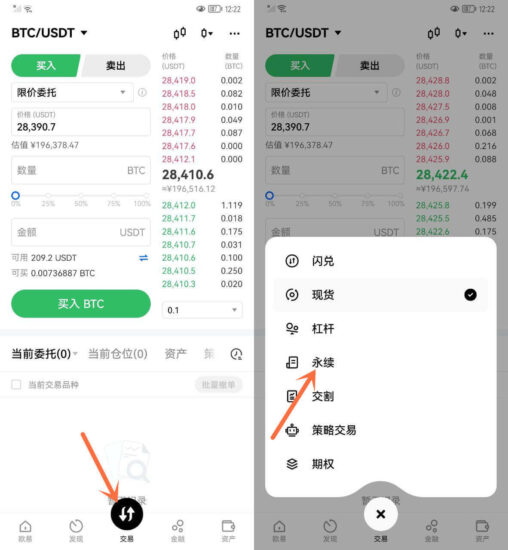
永续合约是加密货币交易的一种衍生品交易,投资者可以在不持有实际数量的加密货币的情况下进行杠杆交易,从而获得更高的投资回报。 一、什么是永续合约交易? 永续合约交易允许投资者根据自己的...
什么是加密货币交易所?
加密货币交易所是一个数字货币的在线市场,类似于股票交易所。它允许用户在其中买入和卖出加密货币,如比特币、以太坊、莱特币等。交易所提供了一个平台,让买卖双方可以安全地进行数字货币的交...

1年前
1年前
1年前
1年前
